What is an image histogram?
Well, it is fairly simple. Consider we have a grayscale image. Its histogram is an array that stores the number of occurence of each grey level. It gives us a representation of the tone distribution.

Source image and its histogram.
If an image is dark, there will be a peak near the lowest tone values. Or the other hand brighter image will have peaks near the maximum tone values.

Dark image

Bright image with associated histogram.
The image histogram can also give us informations about its contrast. An image with a low contrast will have a peak around its median value and most of the histogram values will be concentrated around that peak. Alternatively a highly contrasted image will have peaks around its minimal and maximal tone value as long as sparse low values in between.

Low contrast image

High contrast image
It seems logical that if we stretch the histogram over the whole tone range, we will increase the image constrast. This operation is called histogram equalization. Before going any further, let’s introduce some basic definitions. The first one is the probability density function:
\(P^{[l_s,l_f]}_l = \frac{h_l}{H^{[l_s,l_f]}}\)
With \(0 \le l_s < l_f \le l_{max}[/latex]. Usually [latex]l_{max} = 255[/latex].
[latex]H^{[m,n]}\) is introduced for brevity. It’s the sum of the histogram value over the range \([m,n]\).
\(H^{[m,n]} = \sum_{i=m}^{n}h_i\)
Next is the probability distribution function.
\(C^{[l_s,l_f]}_l = \frac{\sum_{i=l_s}^{l}h_i}{H^{[l_s,l_f]}}\)
Which can be rewritten as:
\(C^{[l_s,l_f]}_l = \sum_{i=l_s}^{l}P^{[l_s,l_f]}_i\)
The mean of the histogram values is also called the image brightness.
\(l_m = \frac{\sum_{i=l_s}^{l_f}i \times h_i}{H^{[l_s,l_f]}}\)
To put it simply,
\(l_m = \sum_{i=l_s}^{l_f}i P^{[l_s,l_f]}_i\)
The aim of histogram equalization is to produce a histogram where each tone has the same number of occurence (uniform distribution). This is equivalent to saying that any tone \(l\) has the same density.
\(P’^{[l_s,l_f]}_{l} = \frac{1}{l_f – ls}\)
Which gives us the ideal probability distribution function.
\(C’^{[l_s,l_f]}_{l} = \sum_{i=l_s}^{l}P’^{[l_s,l_f]}_i = \frac{l-ls}{lf – ls}\)
A way to acheive this is to find \(l’\) that minimizes the difference between \(C’^{[l_s,l_f]}_{l’}\) and \(C^{[l_s,l_f]}_{l}\). In other words, we want to find \(l’\) so that:
\(C^{[l_s,l_f]}_{l} = C’^{[l_s,l_f]}_{l’}\)
Which gives us:
\(l’ = l_s + \big\langle(l_f – l_s) C^{[l_s,l_f]}_l \big\rangle\)
Where \(\langle x \rangle\) is the nearest integer to \(x\).
This technique is sometimes referred as the classical histogram equalization or CHE. The drawback of this method is that it changes the image brightness.
The following source code is performing CHE with \(ls = 0\) and \(l_f = l_{max}\).
This code is using the CImg library.
// We will load a dark grayscale version of the
// classical lena image.
CImg<unsigned char> source;
source.load("dark_lena.png");
unsigned long int lut[256];
unsigned long int histogram[256];
// Build image histogram.
memset(histogram, 0, sizeof(unsigned long int)*256);
cimg_forXY(source, x, y)
{
histogram[source(x,y,0,0)]++;
}
// Compute probality distribution function.
unsigned long int sum = 0;
for(int i=0; i<256; i++)
{
sum += histogram[i];
lut[i] = floor(255.0 * sum / (source.width() * source.height()) + 0.5);
}
// Perform CHE
cimg_forXY(source, x, y)
{
source(x,y,0,0) = lut[(int)source(x, y, 0, 0)];
}
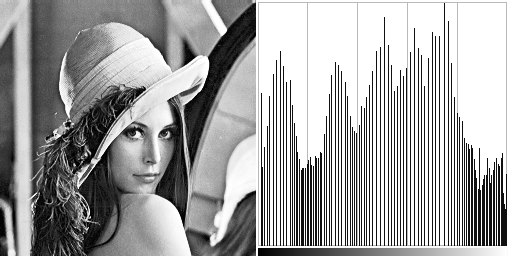
Result of CHE source code.
References:
- David Menotti Gomes. Contrast Enhancement in Digital Imaging using Histogram Equalization. PhD Thesis, June 2008