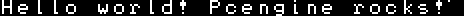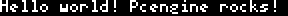Oh hy! I didn’t notice you were here. Please take a seat.
So I were talking about the font. As shown in the following image, the original font already contained uppercase letters.

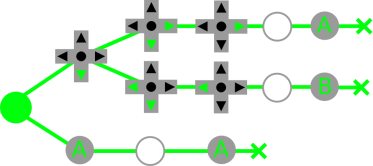
As I wanted to add lowercases and some punctuations, I had to find where and how the font was stored in ROM. The visual editor told me that the font was stored from $7300 to $7a10 in VRAM. So under the code debugger I set an aux write breakpoint (ctrl+w) to these addresses. The breakpoint was triggered at $f7c6 on :
TIA $3740, $0002, $0020
If you look closely at the following image, you’ll notice that there are 2 similar preceding occurrences. This is it! You are looking at the piece of code in charge of decompressing the tile data into VRAM. 
This code supports 4 kind of compression:
- The tile is filled with 0.
- Uncompressed. The data is directly transfered to VRAM.
- Simple RLE encoding.
- Simple RLE encoding with some kind of postprocessing involving XORing consecutive lines.
Laziness told me to avoid writing a little tool to compress the font. So I checked how many uncompresserd char were used and if it was enough to store lowercases. Hopefully there was enough room for all of them. 
At this point I had nearly everything I wanted. There were no need to modify the string display routine. Most of the work done would have been done by the script encoder as the lowercases characters where not contigous. It was not a big deal. Nevertheless I wanted to check if there will be enough room for the translated texts and how much characters could be displayed per screen. Basically you had 16 characters per line and 7 or 11 line depending on the screen. This gave me an idea of the maximal script size. Unfortunately it was too big. So I looked for a fast/small/simple text compression/decompression for 6502 based cpu. I had a quick look at the romhacking.net forum. And it seems that one of the most used technique is DTE (Dual Tile Encoding). It’s a pretty simple approach. A text does not use all the ascii values. Basically you only use upper and lowercases (52 chars), numbers (10) and a dozen punctuation marks. This leaves you with 182 unused values. You can use them to store couples of characters. Bytes with values between 0 and 74 represent a single character and all the others represent a tuple. For example 182 represents ‘ab’, 183 ‘en’ and so on. Here is quick example: Let’s compress the string “abcacbabcabcabba”. First we extract all the characters couples and count them:
- ab : 4
- bc : 3
- ca : 3
- ac : 1
- cb : 1
- ba : 2
- bb : 1
“ab” is the tuple with the highest occurence. We insert it in the symbol table: a,b,c,d=’ab’. And let’s replace it in the original string:“dcacbdcdcdba”. DTE only works on the original symbols. So in the second pass we must avoid the newly inserted symbols. The remaining tuples are :
- ca : 1
- ac : 1
- cb : 1
- ba : 1
The new symbol table is : a,b,c,d=’ab’,e=’ca’,f=’cb’,g=’ba’. In the end “abcacbabcabcabba” becomes “defdcdcdg”. The tricky part is to choose the right substitution sequence that will lead to the smallest possible string. It’s a whole new game and you can stick with choosing the tuple with the highest occurence.
Let’s get back to Alice. I grabbed the infamous lorem ipsum and made a script out of it. I compressed it with DTE. And I still had a lot of unused values. Remember the second pass of our example when I excluded the newly inserted symbol for the occurence counting. If I included it, DTE would in fact have been what is called BPE (Binary Pair Encoding). Here’s the mandatory academical reference : Byte Pair Encoding: A Text Compression Scheme That Accelerates Pattern Matching (1999). Using BPE we would have had for “dcacbdcdcdba”.
- dc : 3
- ca : 1
- ca : 1
- ac : 1
- cb : 1
- bd : 1
- cd : 2
- db : 1
- ba : 1
Let’s add “dc” in the symbol table a,b,c,d=’ab’,e=’dc’. We now have “eacbeedba”. BPE is basically a recursive algorithm. So when we are decoding a string, we must check if it’s part of the tuple symbols (let’s call them “special” symbols). If that’s the case we will have to loop until the decoded symbol does not contain any special symbol. If speed is a concern we may limit the depth of recursion. This means that when we must take the depth of each symbol into consideration. For example imagine we have 2 tuples “dc” and “ca”. Both have the same number of occurence in the string. We may choose “ca” instead of “dc” because it only contains “base” symbols.
Using BPE the “maximal” script was small enough to fit. I made a silly test using some part of Hamlet (here’s the script). You can find the BPE compression/decompression as long as code for generating IPS files in this [archive].
Next : Levels names. Shitty part : they are sprites. Describe pointer tables and all.
All compressed. So I can’t avoid it anymore. Describe the compression scheme.
Got help for level name translation. (show the level names and their translation).
As I have a compressor, reworked the font so that it more or less match ascii. Had to spot where the font was rendered to vram. (link to final font). Simplify script encoder and display routine.
Coming next: Level names. A world of pain and horror!